How to hide an image saved in a folder using cmd mode

1. Which of the following is NOT a valid deadlock
prevention scheme? (GATE CS 2000)
(a) Release all resources before requesting a
new resource
(b) Number the resources uniquely and never request a lower numbered resource than the last one requested.
(c) Never request a resource after releasing any resource
(d) Request and all required resources be allocated before execution.
Answer: (c)
References:
http://www.cs.jhu.edu/~yairamir/cs418/os4/sld013.htm
http://en.wikipedia.org/wiki/Deadlock
2. Let m[0]…m[4] be mutexes (binary semaphores) and P[0] …. P[4] be processes.
Suppose each process P[i] executes the following:
(b) Number the resources uniquely and never request a lower numbered resource than the last one requested.
(c) Never request a resource after releasing any resource
(d) Request and all required resources be allocated before execution.
Answer: (c)
References:
http://www.cs.jhu.edu/~yairamir/cs418/os4/sld013.htm
http://en.wikipedia.org/wiki/Deadlock
2. Let m[0]…m[4] be mutexes (binary semaphores) and P[0] …. P[4] be processes.
Suppose each process P[i] executes the following:
wait (m[i]); wait(m[(i+1) mode
4]);
------
release (m[i]); release
(m[(i+1)mod 4]);
This could cause (GATE
CS 2000)
(a) Thrashing
(b) Deadlock
(c) Starvation, but not deadlock
(d) None of the above
Answer: (b)
Explanation:
You can easily see a deadlock in a situation where..
P[0] has acquired m[0] and waiting for m[1]
P[1] has acquired m[1] and waiting for m[2]
P[2] has acquired m[2] and waiting for m[3]
P[3] has acquired m[3] and waiting for m[0]
3. A graphics card has on board memory of 1 MB. Which of the following modes can the card not support? (GATE CS 2000)
(a) 1600 x 400 resolution with 256 colours on a 17 inch monitor
(b) 1600 x 400 resolution with 16 million colours on a 14 inch monitor
(c) 800 x 400 resolution with 16 million colours on a 17 inch monitor
(d) 800 x 800 resolution with 256 colours on a 14 inch monitor
Answer: (b)
Explanation:
Monitor size doesn’t matter here. So, we can easily deduct that answer should be (b) as this has the highest memory requirements. Let us verify it.
Number of bits required to store a 16M colors pixel = ceil(log2(16*1000000)) = 24
Number of bytes required for 1600 x 400 resolution with 16M colors = (1600 * 400 * 24)/8 which is 192000000 (greater than 1MB).
4 Consider a virtual memory system with FIFO page replacement policy. For an arbitrary page access pattern, increasing the number of page frames in main memory will (GATE CS 2001)
a) Always decrease the number of page faults
b) Always increase the number of page faults
c) Some times increase the number of page faults
d) Never affect the number of page faults
Answer: (c)
Explanation:
Incrementing the number of page frames doesn’t always decrease the page faults (Belady’s Anomaly). For details see http://en.wikipedia.org/wiki/Belady%27s_anomaly
5. Which of the following requires a device driver? (GATE CS 2001)
a) Register
b) Cache
c) Main memory
d) Disk
Answer: (d)
6. Consider a machine with 64 MB physical memory and a 32-bit virtual address space. If the page size is 4KB, what is the approximate size of the page table? (GATE 2001)
(a) 16 MB
(b) 8 MB
(c) 2 MB
(d) 24 MB
Answer: (c)
Explanation:
A page entry is used to get address of physical memory. Here we assume that single level of Paging is happening. So the resulting page table will contain entries for all the pages of the Virtual address space.
(a) Thrashing
(b) Deadlock
(c) Starvation, but not deadlock
(d) None of the above
Answer: (b)
Explanation:
You can easily see a deadlock in a situation where..
P[0] has acquired m[0] and waiting for m[1]
P[1] has acquired m[1] and waiting for m[2]
P[2] has acquired m[2] and waiting for m[3]
P[3] has acquired m[3] and waiting for m[0]
3. A graphics card has on board memory of 1 MB. Which of the following modes can the card not support? (GATE CS 2000)
(a) 1600 x 400 resolution with 256 colours on a 17 inch monitor
(b) 1600 x 400 resolution with 16 million colours on a 14 inch monitor
(c) 800 x 400 resolution with 16 million colours on a 17 inch monitor
(d) 800 x 800 resolution with 256 colours on a 14 inch monitor
Answer: (b)
Explanation:
Monitor size doesn’t matter here. So, we can easily deduct that answer should be (b) as this has the highest memory requirements. Let us verify it.
Number of bits required to store a 16M colors pixel = ceil(log2(16*1000000)) = 24
Number of bytes required for 1600 x 400 resolution with 16M colors = (1600 * 400 * 24)/8 which is 192000000 (greater than 1MB).
4 Consider a virtual memory system with FIFO page replacement policy. For an arbitrary page access pattern, increasing the number of page frames in main memory will (GATE CS 2001)
a) Always decrease the number of page faults
b) Always increase the number of page faults
c) Some times increase the number of page faults
d) Never affect the number of page faults
Answer: (c)
Explanation:
Incrementing the number of page frames doesn’t always decrease the page faults (Belady’s Anomaly). For details see http://en.wikipedia.org/wiki/Belady%27s_anomaly
5. Which of the following requires a device driver? (GATE CS 2001)
a) Register
b) Cache
c) Main memory
d) Disk
Answer: (d)
6. Consider a machine with 64 MB physical memory and a 32-bit virtual address space. If the page size is 4KB, what is the approximate size of the page table? (GATE 2001)
(a) 16 MB
(b) 8 MB
(c) 2 MB
(d) 24 MB
Answer: (c)
Explanation:
A page entry is used to get address of physical memory. Here we assume that single level of Paging is happening. So the resulting page table will contain entries for all the pages of the Virtual address space.
Number of entries in page table =
(virtual address
space size)/(page size)
Using above formula we can say
that there will be 2^(32-12) = 2^20 entries in page table.
No. of bits required to address the 64MB Physical memory = 26.
So there will be 2^(26-12) = 2^14 page frames in the physical memory. And page table needs to store the address of all these 2^14 page frames. Therefore, each page table entry will contain 14 bits address of the page frame and 1 bit for valid-invalid bit.
Since memory is byte addressable. So we take that each page table entry is 16 bits i.e. 2 bytes long.
No. of bits required to address the 64MB Physical memory = 26.
So there will be 2^(26-12) = 2^14 page frames in the physical memory. And page table needs to store the address of all these 2^14 page frames. Therefore, each page table entry will contain 14 bits address of the page frame and 1 bit for valid-invalid bit.
Since memory is byte addressable. So we take that each page table entry is 16 bits i.e. 2 bytes long.
Size of page table =
(total number of page table
entries) *(size of a page table entry)
= (2^20 *2) = 2MB
7. Consider Peterson’s algorithm for mutual exclusion between two concurrent processes i and j. The program executed by process is shown below.
repeat
flag [i] = true;
turn = j;
while ( P ) do no-op;
Enter critical section,
perform actions, then exit critical
section
flag [ i ] = false;
Perform other non-critical
section actions.
until false;
For the program to
guarantee mutual exclusion, the predicate P in the while loop should be (GATE
2001)
a) flag [j] = true and turn = i
b) flag [j] = true and turn = j
c) flag [i] = true and turn = j
d) flag [i] = true and turn = i
Answer: (b)
Basically, Peterson’s algorithm provides guaranteed mutual exclusion by using the two following constructs – flag[] and turn. flag[] controls that the willingness of a process to be entered in critical section. While turn controls the process that is allowed to be entered in critical section. So by replacing P with the following,
flag [j] = true and turn = j
process i will not enter critical section if process j wants to enter critical section and it is process j’s turn to enter critical section. The same concept can be extended for more than two processes. For details, refer the following.
References:
http://en.wikipedia.org/wiki/Peterson%27s_algorithm
8 More than one word are put in one cache block to (GATE 2001)
(a) exploit the temporal locality of reference in a program
(b) exploit the spatial locality of reference in a program
(c) reduce the miss penalty
(d) none of the above
Answer: (b)
Temporal locality refers to the reuse of specific data and/or resources within relatively small time durations. Spatial locality refers to the use of data elements within relatively close storage locations.
To exploit the spatial locality, more than one word are put into cache block.
References:
http://en.wikipedia.org/wiki/Locality_of_reference
9. Which of the following statements is false? (GATE 2001)
a) Virtual memory implements the translation of a program’s address space into physical memory address space
b) Virtual memory allows each program to exceed the size of the primary memory
c) Virtual memory increases the degree of multiprogramming
d) Virtual memory reduces the context switching overhead
Answer: (d)
In a system with virtual memory context switch includes extra overhead in switching of address spaces.
References:
http://www.itee.adfa.edu.au/~spike/CSA2/Lectures00/lecture.vm.htm
10. Consider a set of n tasks with known runtimes r1, r2, … rn to be run on a uniprocessor machine. Which of the following processor scheduling algorithms will result in the maximum throughput? (GATE 2001)
(a) Round-Robin
(b) Shortest-Job-First
(c) Highest-Response-Ratio-Next
(d) First-Come-First-Served
Answer: (b)
11. Suppose the time to service a page fault is on the average 10 milliseconds, while a memory access takes 1 microsecond. Then a 99.99% hit ratio results in average memory access time of (GATE CS 2000)
(a) 1.9999 milliseconds
(b) 1 millisecond
(c) 9.999 microseconds
(d) 1.9999 microseconds
Answer: (d)
Explanation:
a) flag [j] = true and turn = i
b) flag [j] = true and turn = j
c) flag [i] = true and turn = j
d) flag [i] = true and turn = i
Answer: (b)
Basically, Peterson’s algorithm provides guaranteed mutual exclusion by using the two following constructs – flag[] and turn. flag[] controls that the willingness of a process to be entered in critical section. While turn controls the process that is allowed to be entered in critical section. So by replacing P with the following,
flag [j] = true and turn = j
process i will not enter critical section if process j wants to enter critical section and it is process j’s turn to enter critical section. The same concept can be extended for more than two processes. For details, refer the following.
References:
http://en.wikipedia.org/wiki/Peterson%27s_algorithm
8 More than one word are put in one cache block to (GATE 2001)
(a) exploit the temporal locality of reference in a program
(b) exploit the spatial locality of reference in a program
(c) reduce the miss penalty
(d) none of the above
Answer: (b)
Temporal locality refers to the reuse of specific data and/or resources within relatively small time durations. Spatial locality refers to the use of data elements within relatively close storage locations.
To exploit the spatial locality, more than one word are put into cache block.
References:
http://en.wikipedia.org/wiki/Locality_of_reference
9. Which of the following statements is false? (GATE 2001)
a) Virtual memory implements the translation of a program’s address space into physical memory address space
b) Virtual memory allows each program to exceed the size of the primary memory
c) Virtual memory increases the degree of multiprogramming
d) Virtual memory reduces the context switching overhead
Answer: (d)
In a system with virtual memory context switch includes extra overhead in switching of address spaces.
References:
http://www.itee.adfa.edu.au/~spike/CSA2/Lectures00/lecture.vm.htm
10. Consider a set of n tasks with known runtimes r1, r2, … rn to be run on a uniprocessor machine. Which of the following processor scheduling algorithms will result in the maximum throughput? (GATE 2001)
(a) Round-Robin
(b) Shortest-Job-First
(c) Highest-Response-Ratio-Next
(d) First-Come-First-Served
Answer: (b)
11. Suppose the time to service a page fault is on the average 10 milliseconds, while a memory access takes 1 microsecond. Then a 99.99% hit ratio results in average memory access time of (GATE CS 2000)
(a) 1.9999 milliseconds
(b) 1 millisecond
(c) 9.999 microseconds
(d) 1.9999 microseconds
Answer: (d)
Explanation:
Average memory access time =
[(% of page miss)*(time to
service a page fault) +
(% of page
hit)*(memory access time)]/100
So, average memory access time in
microseconds is.
(99.99*1 + 0.01*10*1000)/100 = (99.99+100)/1000 = 199.99/1000 =1.9999 µs
12. Which of the following need not necessarily be saved on a context switch between processes? (GATE CS 2000)
(a) General purpose registers
(b) Translation look-aside buffer
(c) Program counter
(d) All of the above
Answer: (b)
Explanation:
In a process context switch, the state of the first process must be saved somehow, so that, when the scheduler gets back to the execution of the first process, it can restore this state and continue.
The state of the process includes all the registers that the process may be using, especially the program counter, plus any other operating system specific data that may be necessary.
A Translation lookaside buffer (TLB) is a CPU cache that memory management hardware uses to improve virtual address translation speed. A TLB has a fixed number of slots that contain page table entries, which map virtual addresses to physical addresses. On a context switch, some TLB entries can become invalid, since the virtual-to-physical mapping is different. The simplest strategy to deal with this is to completely flush the TLB.
References:
http://en.wikipedia.org/wiki/Context_switch
http://en.wikipedia.org/wiki/Translation_lookaside_buffer#Context_switch
13. Where does the swap space reside ? (GATE 2001)
(a) RAM
(b) Disk
(c) ROM
(d) On-chip cache
Answer: (b)
Explanation:
Swap space is an area on disk that temporarily holds a process memory image. When physical memory demand is sufficiently low, process memory images are brought back into physical memory from the swap area. Having sufficient swap space enables the system to keep some physical memory free at all times.
References:
http://docs.hp.com/en/B2355-90672/ch06s02.html
14. Which of the following does not interrupt a running process? (GATE CS 2001)
(a) A device
(b) Timer
(c) Scheduler process
(d) Power failure
Answer: (c)
Explanation:
Scheduler process doesn’t interrupt any process, it’s Job is to select the processes for following three purposes.
Long-term scheduler(or job scheduler) –selects which processes should be brought into the ready queue
Short-term scheduler(or CPU scheduler) –selects which process should be executed next and allocates CPU.
Mid-term Scheduler (Swapper)- present in all systems with virtual memory, temporarily removes processes from main memory and places them on secondary memory (such as a disk drive) or vice versa. The mid-term scheduler may decide to swap out a process which has not been active for some time, or a process which has a low priority, or a process which is page faulting frequently, or a process which is taking up a large amount of memory in order to free up main memory for other processes, swapping the process back in later when more memory is available, or when the process has been unblocked and is no longer waiting for a resource.
15. Which of the following scheduling algorithms is non-preemptive? (GATE CS 2002)
a) Round Robin
b) First-In First-Out
c) Multilevel Queue Scheduling
d) Multilevel Queue Scheduling with Feedback
Answer: (b)
16. Using a larger block size in a fixed block size file system leads to (GATE CS 2003)
a) better disk throughput but poorer disk space utilization
b) better disk throughput and better disk space utilization
c) poorer disk throughput but better disk space utilization
d) poorer disk throughput and poorer disk space utilization
Answer (a)
If block size is large then seek time is less (fewer blocks to seek) and disk performance is improved, but remember larger block size also causes waste of disk space.
17. Consider the following statements with respect to user-level threads and kernel supported threads
i. context switch is faster with kernel-supported threads
ii. for user-level threads, a system call can block the entire process
iii. Kernel supported threads can be scheduled independently
iv. User level threads are transparent to the kernel
Which of the above statements are true? (GATE CS 2004)
a) (ii), (iii) and (iv) only
b) (ii) and (iii) only
c) (i) and (iii) only
d) (i) and (ii) only
Answer(a)
http://en.wikipedia.org/wiki/Thread_%28computer_science%29
18. The minimum number of page frames that must be allocated to a running process in a virtual memory environment is determined by (GATE CS 2004)
a) the instruction set architecture
b) page size
c) physical memory size
d) number of processes in memory
Answer (a)
Each process needs minimum number of pages based on instruction set architecture. Example IBM 370: 6 pages to handle MVC (storage to storage move) instruction
Instruction is 6 bytes, might span 2 pages.
2 pages to handle from.
2 pages to handle to.
19. In a system with 32 bit virtual addresses and 1 KB page size, use of one-level page tables for virtual to physical address translation is not practical because of (GATE CS 2003)
a) the large amount of internal fragmentation
b) the large amount of external fragmentation
c) the large memory overhead in maintaining page tables
d) the large computation overhead in the translation process
Answer (c)
Since page size is too small it will make size of page tables huge.
(99.99*1 + 0.01*10*1000)/100 = (99.99+100)/1000 = 199.99/1000 =1.9999 µs
12. Which of the following need not necessarily be saved on a context switch between processes? (GATE CS 2000)
(a) General purpose registers
(b) Translation look-aside buffer
(c) Program counter
(d) All of the above
Answer: (b)
Explanation:
In a process context switch, the state of the first process must be saved somehow, so that, when the scheduler gets back to the execution of the first process, it can restore this state and continue.
The state of the process includes all the registers that the process may be using, especially the program counter, plus any other operating system specific data that may be necessary.
A Translation lookaside buffer (TLB) is a CPU cache that memory management hardware uses to improve virtual address translation speed. A TLB has a fixed number of slots that contain page table entries, which map virtual addresses to physical addresses. On a context switch, some TLB entries can become invalid, since the virtual-to-physical mapping is different. The simplest strategy to deal with this is to completely flush the TLB.
References:
http://en.wikipedia.org/wiki/Context_switch
http://en.wikipedia.org/wiki/Translation_lookaside_buffer#Context_switch
13. Where does the swap space reside ? (GATE 2001)
(a) RAM
(b) Disk
(c) ROM
(d) On-chip cache
Answer: (b)
Explanation:
Swap space is an area on disk that temporarily holds a process memory image. When physical memory demand is sufficiently low, process memory images are brought back into physical memory from the swap area. Having sufficient swap space enables the system to keep some physical memory free at all times.
References:
http://docs.hp.com/en/B2355-90672/ch06s02.html
14. Which of the following does not interrupt a running process? (GATE CS 2001)
(a) A device
(b) Timer
(c) Scheduler process
(d) Power failure
Answer: (c)
Explanation:
Scheduler process doesn’t interrupt any process, it’s Job is to select the processes for following three purposes.
Long-term scheduler(or job scheduler) –selects which processes should be brought into the ready queue
Short-term scheduler(or CPU scheduler) –selects which process should be executed next and allocates CPU.
Mid-term Scheduler (Swapper)- present in all systems with virtual memory, temporarily removes processes from main memory and places them on secondary memory (such as a disk drive) or vice versa. The mid-term scheduler may decide to swap out a process which has not been active for some time, or a process which has a low priority, or a process which is page faulting frequently, or a process which is taking up a large amount of memory in order to free up main memory for other processes, swapping the process back in later when more memory is available, or when the process has been unblocked and is no longer waiting for a resource.
15. Which of the following scheduling algorithms is non-preemptive? (GATE CS 2002)
a) Round Robin
b) First-In First-Out
c) Multilevel Queue Scheduling
d) Multilevel Queue Scheduling with Feedback
Answer: (b)
16. Using a larger block size in a fixed block size file system leads to (GATE CS 2003)
a) better disk throughput but poorer disk space utilization
b) better disk throughput and better disk space utilization
c) poorer disk throughput but better disk space utilization
d) poorer disk throughput and poorer disk space utilization
Answer (a)
If block size is large then seek time is less (fewer blocks to seek) and disk performance is improved, but remember larger block size also causes waste of disk space.
17. Consider the following statements with respect to user-level threads and kernel supported threads
i. context switch is faster with kernel-supported threads
ii. for user-level threads, a system call can block the entire process
iii. Kernel supported threads can be scheduled independently
iv. User level threads are transparent to the kernel
Which of the above statements are true? (GATE CS 2004)
a) (ii), (iii) and (iv) only
b) (ii) and (iii) only
c) (i) and (iii) only
d) (i) and (ii) only
Answer(a)
http://en.wikipedia.org/wiki/Thread_%28computer_science%29
18. The minimum number of page frames that must be allocated to a running process in a virtual memory environment is determined by (GATE CS 2004)
a) the instruction set architecture
b) page size
c) physical memory size
d) number of processes in memory
Answer (a)
Each process needs minimum number of pages based on instruction set architecture. Example IBM 370: 6 pages to handle MVC (storage to storage move) instruction
Instruction is 6 bytes, might span 2 pages.
2 pages to handle from.
2 pages to handle to.
19. In a system with 32 bit virtual addresses and 1 KB page size, use of one-level page tables for virtual to physical address translation is not practical because of (GATE CS 2003)
a) the large amount of internal fragmentation
b) the large amount of external fragmentation
c) the large memory overhead in maintaining page tables
d) the large computation overhead in the translation process
Answer (c)
Since page size is too small it will make size of page tables huge.
Size of page table =
(total number of page table
entries) *(size of a page table entry)
Let us see how many entries are
there in page table
Number of entries in page table =
(virtual
address space size)/(page size)
= (2^32)/(2^10)
= 2^22
Now, let us see how big each entry
is.
If size of physical memory is 512 MB then number of bits required to address a byte in 512 MB is 29. So, there will be (512MB)/(1KB) = (2^29)/(2^10) page frames in physical memory. To address a page frame 19 bits are required. Therefore, each entry in page table is required to have 19 bits.
If size of physical memory is 512 MB then number of bits required to address a byte in 512 MB is 29. So, there will be (512MB)/(1KB) = (2^29)/(2^10) page frames in physical memory. To address a page frame 19 bits are required. Therefore, each entry in page table is required to have 19 bits.
Note that page table entry also holds auxiliary information about the
page such
as a present bit, a dirty or modified bit, address space or process ID
information,
amongst others. So size of page table
> (total number of page
table entries) *(size of a page table entry)
> (2^22 *19) bytes
> 9.5 MB
And this much memory is required
for each process because each process maintains its own page table. Also, size
of page table will be more for physical memory more than 512MB. Therefore, it
is advised to use multilevel page table for such scenarios.
References:
http://barbara.stattenfield.org/ta/cs162/section-notes/sec8.txt
http://en.wikipedia.org/wiki/Page_table
20. A process executes the code
References:
http://barbara.stattenfield.org/ta/cs162/section-notes/sec8.txt
http://en.wikipedia.org/wiki/Page_table
20. A process executes the code
fork ();
fork ();
fork ();
The total number of
child processes created is
(A) 3
(B) 4
(C) 7
(D) 8
Answer (C)
Let us put some label names for the three lines
(A) 3
(B) 4
(C) 7
(D) 8
Answer (C)
Let us put some label names for the three lines
fork (); // Line 1
fork (); // Line 2
fork (); // Line 3
L1 // There will be 1 child process created
by line 1
/ \
L2 L2
// There will be 2 child processes created by line 2
/
\ / \
L3 L3 L3
L3 // There will be 4 child
processes created by line 3
We can also use direct formula to
get the number of child processes. With n fork statements, there are always 2^n
– 1 child processes. Also see this post for more details.
21. consider the 3 processes, P1, P2 and P3 shown in the table
21. consider the 3 processes, P1, P2 and P3 shown in the table
Process Arrival time Time unit required
P1 0 5
P2 1 7
P3 3 4
The completion order
of the 3 processes under the policies FCFS and RRS (round robin scheduling with
CPU quantum of 2 time units) are
(A) FCFS: P1, P2, P3 RR2: P1, P2, P3
(B) FCFS: P1, P3, P2 RR2: P1, P3, P2
(C) FCFS: P1, P2, P3 RR2: P1, P3, P2
(D) FCFS: P1, P3, P2 RR2: P1, P2, P3
Answer (C)
22. Consider the virtual page reference string
1, 2, 3, 2, 4, 1, 3, 2, 4, 1
On a demand paged virtual memory system running on a computer system that main memory size of 3 pages frames which are initially empty. Let LRU, FIFO and OPTIMAL denote the number of page faults under the corresponding page replacements policy. Then
(A) OPTIMAL < LRU < FIFO
(B) OPTIMAL < FIFO < LRU
(C) OPTIMAL = LRU
(D) OPTIMAL = FIFO
Answer (B)
The OPTIMAL will be 5, FIFO 6 and LRU 9.
23. A file system with 300 GByte uses a file descriptor with 8 direct block address. 1 indirect block address and 1 doubly indirect block address. The size of each disk block is 128 Bytes and the size of each disk block address is 8 Bytes. The maximum possible file size in this file system is
(A) 3 Kbytes
(B) 35 Kbytes
(C) 280 Bytes
(D) Dependent on the size of the disk
Answer (B)
Total number of possible addresses stored in a disk block = 128/8 = 16
Maximum number of addressable bytes due to direct address block = 8*128
Maximum number of addressable bytes due to 1 single indirect address block = 16*128
Maximum number of addressable bytes due to 1 double indirect address block = 16*16*128
The maximum possible file size = 8*128 + 16*128 + 16*16*128 = 35KB
24) A thread is usually defined as a ‘light weight process’ because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the followings is TRUE?
(A) On per-thread basis, the OS maintains only CPU register state
(B) The OS does not maintain a separate stack for each thread
(C) On per-thread basis, the OS does not maintain virtual memory state
(D) On per thread basis, the OS maintains only scheduling and accounting information.
Answer (A)
Threads are called ‘light weight process’ because they only need storage for stack and registers. They don’t need separate space for other things like code segment, global data, etc
25) Let the page fault service time be 10ms in a computer with average memory access time being 20ns. If one page fault is generated for every 10^6 memory accesses, what is the effective access time for the memory?
(A) 21ns
(B) 30ns
(C) 23ns
(D) 35ns
Answer (B)
(A) FCFS: P1, P2, P3 RR2: P1, P2, P3
(B) FCFS: P1, P3, P2 RR2: P1, P3, P2
(C) FCFS: P1, P2, P3 RR2: P1, P3, P2
(D) FCFS: P1, P3, P2 RR2: P1, P2, P3
Answer (C)
22. Consider the virtual page reference string
1, 2, 3, 2, 4, 1, 3, 2, 4, 1
On a demand paged virtual memory system running on a computer system that main memory size of 3 pages frames which are initially empty. Let LRU, FIFO and OPTIMAL denote the number of page faults under the corresponding page replacements policy. Then
(A) OPTIMAL < LRU < FIFO
(B) OPTIMAL < FIFO < LRU
(C) OPTIMAL = LRU
(D) OPTIMAL = FIFO
Answer (B)
The OPTIMAL will be 5, FIFO 6 and LRU 9.
23. A file system with 300 GByte uses a file descriptor with 8 direct block address. 1 indirect block address and 1 doubly indirect block address. The size of each disk block is 128 Bytes and the size of each disk block address is 8 Bytes. The maximum possible file size in this file system is
(A) 3 Kbytes
(B) 35 Kbytes
(C) 280 Bytes
(D) Dependent on the size of the disk
Answer (B)
Total number of possible addresses stored in a disk block = 128/8 = 16
Maximum number of addressable bytes due to direct address block = 8*128
Maximum number of addressable bytes due to 1 single indirect address block = 16*128
Maximum number of addressable bytes due to 1 double indirect address block = 16*16*128
The maximum possible file size = 8*128 + 16*128 + 16*16*128 = 35KB
24) A thread is usually defined as a ‘light weight process’ because an operating system (OS) maintains smaller data structures for a thread than for a process. In relation to this, which of the followings is TRUE?
(A) On per-thread basis, the OS maintains only CPU register state
(B) The OS does not maintain a separate stack for each thread
(C) On per-thread basis, the OS does not maintain virtual memory state
(D) On per thread basis, the OS maintains only scheduling and accounting information.
Answer (A)
Threads are called ‘light weight process’ because they only need storage for stack and registers. They don’t need separate space for other things like code segment, global data, etc
25) Let the page fault service time be 10ms in a computer with average memory access time being 20ns. If one page fault is generated for every 10^6 memory accesses, what is the effective access time for the memory?
(A) 21ns
(B) 30ns
(C) 23ns
(D) 35ns
Answer (B)
Let P be the page fault rate
Effective Memory Access Time = p * (page fault service time) +
(1
- p) * (Memory access time)
= (
1/(10^6) )* 10 * (10^6) ns +
(1
- 1/(10^6)) * 20 ns
= 30
ns (approx)
26) An application loads 100 libraries at startup. Loading each library requires exactly one disk access. The seek time of the disk to a random location is given as 10ms. Rotational speed of disk is 6000rpm. If all 100 libraries are loaded from random locations on the disk, how long does it take to load all libraries? (The time to transfer data from the disk block once the head has been positioned at the start of the block may be neglected)
(A) 0.50s
(B) 1.50s
(C) 1.25s
(D) 1.00s
Answer (B)
Since transfer time can be neglected, the average access time is sum of average seek time and average rotational latency. Average seek time for a random location time is given as 10 ms. The average rotational latency is half of the time needed for complete rotation. It is given that 6000 rotations need 1 minute. So one rotation will take 60/6000 seconds which is 10 ms. Therefore average rotational latency is half of 10 ms, which is 5ms.
Average disk access time = seek time + rotational latency
= 10 ms +
5 ms
= 15 ms
For 100 libraries, the average disk access time will be 15*100 ms
27. Consider the following table of arrival time and burst time for three processes P0, P1 and P2.
Process Arrival time Burst Time
P0 0 ms 9 ms
P1 1 ms 4 ms
P2 2 ms 9 ms
The pre-emptive
shortest job first scheduling algorithm is used. Scheduling is carried out only
at arrival or completion of processes. What is the average waiting time for the
three processes?
(A) 5.0 ms
(B) 4.33 ms
(C) 6.33 ms
(D) 7.33 ms
Answer: – (A)
Process P0 is allocated processor at 0 ms as there is no other process in ready queue. P0 is preempted after 1 ms as P1 arrives at 1 ms and burst time for P1 is less than remaining time of P0. P1 runs for 4ms. P2 arrived at 2 ms but P1 continued as burst time of P2 is longer than P1. After P1 completes, P0 is scheduled again as the remaining time for P0 is less than the burst time of P2.
P0 waits for 4 ms, P1 waits for 0 ms amd P2 waits for 11 ms. So average waiting time is (0+4+11)/3 = 5.
28) Let the time taken to switch between user and kernel modes of execution be t1 while the time taken to switch between two processes be t2. Which of the following is TRUE? (GATE CS 2011)
(A) t1 > t2
(B) t1 = t2
(C) t1 < t2
(D) Nothing can be said about the relation between t1 and t2
Answer: - (C)
Process switching involves mode switch. Context switching can occur only in kernel mode.
29) A system uses FIFO policy for page replacement. It has 4 page frames with no pages loaded to begin with. The system first accesses 100 distinct pages in some order and then accesses the same 100 pages but now in the reverse order. How many page faults will occur? (GATE CS 2010)
(A) 196
(B) 192
(C) 197
(D) 195
Answer (A)
Access to 100 pages will cause 100 page faults. When these pages are accessed in reverse order, the first four accesses will node cause page fault. All other access to pages will cause page faults. So total number of page faults will be 100 + 96.
30) Which of the following statements are true? (GATE CS 2010)
I. Shortest remaining time first scheduling may cause starvation
II. Preemptive scheduling may cause starvation
III. Round robin is better than FCFS in terms of response time
(A) I only
(B) I and III only
(C) II and III only
(D) I, II and III
Answer (D)
I) Shortest remaining time first scheduling is a preemptive version of shortest job scheduling. It may cause starvation as shorter processes may keep coming and a long CPU burst process never gets CPU.
II) Preemption may cause starvation. If priority based scheduling with preemption is used, then a low priority process may never get CPU.
III) Round Robin Scheduling improves response time as all processes get CPU after a specified time.
31) Consider the methods used by processes P1 and P2 for accessing their critical sections whenever needed, as given below. The initial values of shared boolean variables S1 and S2 are randomly assigned.
(A) 5.0 ms
(B) 4.33 ms
(C) 6.33 ms
(D) 7.33 ms
Answer: – (A)
Process P0 is allocated processor at 0 ms as there is no other process in ready queue. P0 is preempted after 1 ms as P1 arrives at 1 ms and burst time for P1 is less than remaining time of P0. P1 runs for 4ms. P2 arrived at 2 ms but P1 continued as burst time of P2 is longer than P1. After P1 completes, P0 is scheduled again as the remaining time for P0 is less than the burst time of P2.
P0 waits for 4 ms, P1 waits for 0 ms amd P2 waits for 11 ms. So average waiting time is (0+4+11)/3 = 5.
28) Let the time taken to switch between user and kernel modes of execution be t1 while the time taken to switch between two processes be t2. Which of the following is TRUE? (GATE CS 2011)
(A) t1 > t2
(B) t1 = t2
(C) t1 < t2
(D) Nothing can be said about the relation between t1 and t2
Answer: - (C)
Process switching involves mode switch. Context switching can occur only in kernel mode.
29) A system uses FIFO policy for page replacement. It has 4 page frames with no pages loaded to begin with. The system first accesses 100 distinct pages in some order and then accesses the same 100 pages but now in the reverse order. How many page faults will occur? (GATE CS 2010)
(A) 196
(B) 192
(C) 197
(D) 195
Answer (A)
Access to 100 pages will cause 100 page faults. When these pages are accessed in reverse order, the first four accesses will node cause page fault. All other access to pages will cause page faults. So total number of page faults will be 100 + 96.
30) Which of the following statements are true? (GATE CS 2010)
I. Shortest remaining time first scheduling may cause starvation
II. Preemptive scheduling may cause starvation
III. Round robin is better than FCFS in terms of response time
(A) I only
(B) I and III only
(C) II and III only
(D) I, II and III
Answer (D)
I) Shortest remaining time first scheduling is a preemptive version of shortest job scheduling. It may cause starvation as shorter processes may keep coming and a long CPU burst process never gets CPU.
II) Preemption may cause starvation. If priority based scheduling with preemption is used, then a low priority process may never get CPU.
III) Round Robin Scheduling improves response time as all processes get CPU after a specified time.
31) Consider the methods used by processes P1 and P2 for accessing their critical sections whenever needed, as given below. The initial values of shared boolean variables S1 and S2 are randomly assigned.
Method Used by P1
while (S1 == S2) ;
Critica1 Section
S1 = S2;
Method Used by P2
while (S1 != S2) ;
Critica1 Section
S2 = not (S1);
Which one of the
following statements describes the properties achieved? (GATE CS 2010)
(A) Mutual exclusion but not progress
(B) Progress but not mutual exclusion
(C) Neither mutual exclusion nor progress
(D) Both mutual exclusion and progress
Answer (A)
It can be easily observed that the Mutual Exclusion requirement is satisfied by the above solution, P1 can enter critical section only if S1 is not equal to S2, and P2 can enter critical section only if S1 is equal to S2.
Progress Requirement is not satisfied. Let us first see definition of Progress Requirement.
Progress Requirement: If no process is executing in its critical section and there exist some processes that wishes to enter their critical section, then the selection of the processes that will enter the critical section next cannot be postponed indefinitely.
If P1 or P2 want to re-enter the critical section, then they cannot even if there is other process running in critical section.
32) In which one of the following page replacement policies, Belady’s anomaly may occur?
(A) FIFO
(B) Optimal
(C) LRU
(D) MRU
Answer (A)
Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm.
See the wiki page for an example of increasing page faults with number of page frames.
33) The essential content(s) in each entry of a page table is / are
(A) Virtual page number
(B) Page frame number
(C) Both virtual page number and page frame number
(D) Access right information
Answer (B)
A page table entry must contain Page frame number. Virtual page number is typically used as index in page table to get the corresponding page frame number. See this for details.
34) Consider a system with 4 types of resources R1 (3 units), R2 (2 units), R3 (3 units), R4 (2 units). A non-preemptive resource allocation policy is used. At any given instance, a request is not entertained if it cannot be completely satisfied. Three processes P1, P2, P3 request the sources as follows if executed independently.
(A) Mutual exclusion but not progress
(B) Progress but not mutual exclusion
(C) Neither mutual exclusion nor progress
(D) Both mutual exclusion and progress
Answer (A)
It can be easily observed that the Mutual Exclusion requirement is satisfied by the above solution, P1 can enter critical section only if S1 is not equal to S2, and P2 can enter critical section only if S1 is equal to S2.
Progress Requirement is not satisfied. Let us first see definition of Progress Requirement.
Progress Requirement: If no process is executing in its critical section and there exist some processes that wishes to enter their critical section, then the selection of the processes that will enter the critical section next cannot be postponed indefinitely.
If P1 or P2 want to re-enter the critical section, then they cannot even if there is other process running in critical section.
32) In which one of the following page replacement policies, Belady’s anomaly may occur?
(A) FIFO
(B) Optimal
(C) LRU
(D) MRU
Answer (A)
Belady’s anomaly proves that it is possible to have more page faults when increasing the number of page frames while using the First in First Out (FIFO) page replacement algorithm.
See the wiki page for an example of increasing page faults with number of page frames.
33) The essential content(s) in each entry of a page table is / are
(A) Virtual page number
(B) Page frame number
(C) Both virtual page number and page frame number
(D) Access right information
Answer (B)
A page table entry must contain Page frame number. Virtual page number is typically used as index in page table to get the corresponding page frame number. See this for details.
34) Consider a system with 4 types of resources R1 (3 units), R2 (2 units), R3 (3 units), R4 (2 units). A non-preemptive resource allocation policy is used. At any given instance, a request is not entertained if it cannot be completely satisfied. Three processes P1, P2, P3 request the sources as follows if executed independently.
Process P1:
t=0: requests 2 units of R2
t=1: requests 1 unit of R3
t=3: requests 2 units of R1
t=5: releases 1 unit of R2
and 1 unit of R1.
t=7: releases 1 unit of R3
t=8: requests 2 units of R4
t=10: Finishes
Process P2:
t=0: requests 2 units of R3
t=2: requests 1 unit of R4
t=4: requests 1 unit of R1
t=6: releases 1 unit of R3
t=8: Finishes
Process P3:
t=0: requests 1 unit of R4
t=2: requests 2 units of R1
t=5: releases 2 units of R1
t=7: requests 1 unit of R2
t=8: requests 1 unit of R3
t=9: Finishes
Which one of the
following statements is TRUE if all three processes run concurrently starting
at time t=0?
(A) All processes will finish without any deadlock
(B) Only P1 and P2 will be in deadlock.
(C) Only P1 and P3 will be in a deadlock.
(D) All three processes will be in deadlock
Answer (A)
We can apply the following Deadlock Detection algorithm and see that there is no process waiting indefinitely for a resource. See this for deadlock detection algorithm.
35) Consider a disk system with 100 cylinders. The requests to access the cylinders occur in following sequence:
4, 34, 10, 7, 19, 73, 2, 15, 6, 20
Assuming that the head is currently at cylinder 50, what is the time taken to satisfy all requests if it takes 1ms to move from one cylinder to adjacent one and shortest seek time first policy is used?
(A) 95ms
(B) 119ms
(C) 233ms
(D) 276ms
Answer (B)
4, 34, 10, 7, 19, 73, 2, 15, 6, 20
Since shortest seek time first policy is used, head will first move to 34. This move will cause 16*1 ms. After 34, head will move to 20 which will cause 14*1 ms. And so on. So cylinders are accessed in following order 34, 20, 19, 15, 10, 7, 6, 4, 2, 73 and total time will be (16 + 14 + 1 + 4 + 5 + 3 + 1 + 2 + 2 + 71)*1 = 119 ms.
36) In the following process state transition diagram for a uniprocessor system, assume that there are always some processes in the ready state: Now consider the following statements:

I. If a process makes a transition D, it would result in another process making transition A immediately.
II. A process P2 in blocked state can make transition E while another process P1 is in running state.
III. The OS uses preemptive scheduling.
IV. The OS uses non-preemptive scheduling.
Which of the above statements are TRUE?
(A) I and II
(B) I and III
(C) II and III
(D) II and IV
Answer (C)
I is false. If a process makes a transition D, it would result in another process making transition B, not A.
II is true. A process can move to ready state when I/O completes irrespective of other process being in running state or not.
III is true because there is a transition from running to ready state.
IV is false as the OS uses preemptive scheduling.
37) The enter_CS() and leave_CS() functions to implement critical section of a process are realized using test-and-set instruction as follows:
(A) All processes will finish without any deadlock
(B) Only P1 and P2 will be in deadlock.
(C) Only P1 and P3 will be in a deadlock.
(D) All three processes will be in deadlock
Answer (A)
We can apply the following Deadlock Detection algorithm and see that there is no process waiting indefinitely for a resource. See this for deadlock detection algorithm.
35) Consider a disk system with 100 cylinders. The requests to access the cylinders occur in following sequence:
4, 34, 10, 7, 19, 73, 2, 15, 6, 20
Assuming that the head is currently at cylinder 50, what is the time taken to satisfy all requests if it takes 1ms to move from one cylinder to adjacent one and shortest seek time first policy is used?
(A) 95ms
(B) 119ms
(C) 233ms
(D) 276ms
Answer (B)
4, 34, 10, 7, 19, 73, 2, 15, 6, 20
Since shortest seek time first policy is used, head will first move to 34. This move will cause 16*1 ms. After 34, head will move to 20 which will cause 14*1 ms. And so on. So cylinders are accessed in following order 34, 20, 19, 15, 10, 7, 6, 4, 2, 73 and total time will be (16 + 14 + 1 + 4 + 5 + 3 + 1 + 2 + 2 + 71)*1 = 119 ms.
36) In the following process state transition diagram for a uniprocessor system, assume that there are always some processes in the ready state: Now consider the following statements:
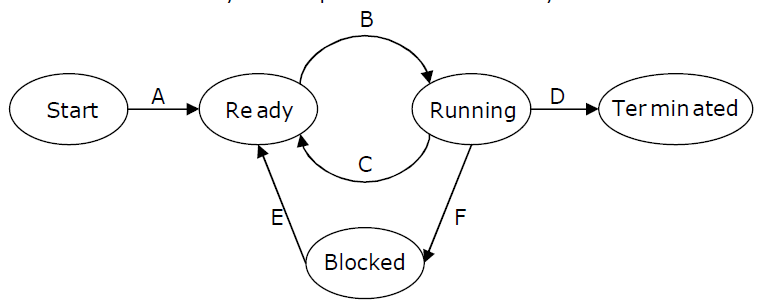
I. If a process makes a transition D, it would result in another process making transition A immediately.
II. A process P2 in blocked state can make transition E while another process P1 is in running state.
III. The OS uses preemptive scheduling.
IV. The OS uses non-preemptive scheduling.
Which of the above statements are TRUE?
(A) I and II
(B) I and III
(C) II and III
(D) II and IV
Answer (C)
I is false. If a process makes a transition D, it would result in another process making transition B, not A.
II is true. A process can move to ready state when I/O completes irrespective of other process being in running state or not.
III is true because there is a transition from running to ready state.
IV is false as the OS uses preemptive scheduling.
37) The enter_CS() and leave_CS() functions to implement critical section of a process are realized using test-and-set instruction as follows:
void enter_CS(X)
{
while test-and-set(X) ;
}
void leave_CS(X)
{
X = 0;
}
In the above solution,
X is a memory location associated with the CS and is initialized to 0. Now
consider the following statements:
I. The above solution to CS problem is deadlock-free
II. The solution is starvation free.
III. The processes enter CS in FIFO order.
IV More than one process can enter CS at the same time.
Which of the above statements is TRUE?
(A) I only
(B) I and II
(C) II and III
(D) IV only
Answer (A)
The above solution is a simple test-and-set solution that makes sure that deadlock doesn’t occur, but it doesn’t use any queue to avoid starvation or to have FIFO order.
38) A multilevel page table is preferred in comparison to a single level page table for translating virtual address to physical address because
(A) It reduces the memory access time to read or write a memory location.
(B) It helps to reduce the size of page table needed to implement the virtual address space of a process.
(C) It is required by the translation lookaside buffer.
(D) It helps to reduce the number of page faults in page replacement algorithms.
Answer (B)
The size of page table may become too big (See this) to fit in contiguous space. That is why page tables are typically divided in levels.
39) The data blocks of a very large file in the Unix file system are allocated using
(A) contiguous allocation
(B) linked allocation
(C) indexed allocation
(D) an extension of indexed allocation
Answer (D)
The Unix file system uses an extension of indexed allocation. It uses direct blocks, single indirect blocks, double indirect blocks and triple indirect blocks. Following diagram shows implementation of Unix file system. The diagram is taken from Operating System Concept book.

40) The P and V operations on counting semaphores, where s is a counting semaphore, are defined as follows:
I. The above solution to CS problem is deadlock-free
II. The solution is starvation free.
III. The processes enter CS in FIFO order.
IV More than one process can enter CS at the same time.
Which of the above statements is TRUE?
(A) I only
(B) I and II
(C) II and III
(D) IV only
Answer (A)
The above solution is a simple test-and-set solution that makes sure that deadlock doesn’t occur, but it doesn’t use any queue to avoid starvation or to have FIFO order.
38) A multilevel page table is preferred in comparison to a single level page table for translating virtual address to physical address because
(A) It reduces the memory access time to read or write a memory location.
(B) It helps to reduce the size of page table needed to implement the virtual address space of a process.
(C) It is required by the translation lookaside buffer.
(D) It helps to reduce the number of page faults in page replacement algorithms.
Answer (B)
The size of page table may become too big (See this) to fit in contiguous space. That is why page tables are typically divided in levels.
39) The data blocks of a very large file in the Unix file system are allocated using
(A) contiguous allocation
(B) linked allocation
(C) indexed allocation
(D) an extension of indexed allocation
Answer (D)
The Unix file system uses an extension of indexed allocation. It uses direct blocks, single indirect blocks, double indirect blocks and triple indirect blocks. Following diagram shows implementation of Unix file system. The diagram is taken from Operating System Concept book.

40) The P and V operations on counting semaphores, where s is a counting semaphore, are defined as follows:
P(s) : s = s - 1;
if (s < 0) then wait;
V(s) : s = s + 1;
if (s <= 0) then wakeup a
process waiting on s;
Assume that Pb and Vb
the wait and signal operations on binary semaphores are provided. Two binary
semaphores Xb and Yb are used to implement the semaphore operations P(s) and
V(s) as follows:
P(s) : Pb(Xb);
s = s - 1;
if (s < 0) {
Vb(Xb) ;
Pb(Yb) ;
}
else Vb(Xb);
V(s) : Pb(Xb) ;
s = s + 1;
if (s <= 0) Vb(Yb) ;
Vb(Xb) ;
The initial values of
Xb and Yb are respectively
(A) 0 and 0
(B) 0 and 1
(C) 1 and 0
(D) 1 and 1
Answer (C)
Both P(s) and V(s) operations are perform Pb(xb) as first step. If Xb is 0, then all processes executing these operations will be blocked. Therefore, Xb must be 1.
If Yb is 1, it may become possible that two processes can execute P(s) one after other (implying 2 processes in critical section). Consider the case when s = 1, y = 1. So Yb must be 0.
41) Which of the following statements about synchronous and asynchronous I/O is NOT true?
(A) An ISR is invoked on completion of I/O in synchronous I/O but not in asynchronous I/O
(B) In both synchronous and asynchronous I/O, an ISR (Interrupt Service Routine) is invoked after completion of the I/O
(C) A process making a synchronous I/O call waits until I/O is complete, but a process making an asynchronous I/O call does not wait for completion of the I/O
(D) In the case of synchronous I/O, the process waiting for the completion of I/O is woken up by the ISR that is invoked after the completion of I/O
Answer (A)
In both Synchronous and Asynchronous, an interrupt is generated on completion of I/O. In Synchronous, interrupt is generated to wake up the process waiting for I/O. In Asynchronous, interrupt is generated to inform the process that the I/O is complete and it can process the data from the I/O operation. See this for more details.
42) A process executes the following code
(A) 0 and 0
(B) 0 and 1
(C) 1 and 0
(D) 1 and 1
Answer (C)
Both P(s) and V(s) operations are perform Pb(xb) as first step. If Xb is 0, then all processes executing these operations will be blocked. Therefore, Xb must be 1.
If Yb is 1, it may become possible that two processes can execute P(s) one after other (implying 2 processes in critical section). Consider the case when s = 1, y = 1. So Yb must be 0.
41) Which of the following statements about synchronous and asynchronous I/O is NOT true?
(A) An ISR is invoked on completion of I/O in synchronous I/O but not in asynchronous I/O
(B) In both synchronous and asynchronous I/O, an ISR (Interrupt Service Routine) is invoked after completion of the I/O
(C) A process making a synchronous I/O call waits until I/O is complete, but a process making an asynchronous I/O call does not wait for completion of the I/O
(D) In the case of synchronous I/O, the process waiting for the completion of I/O is woken up by the ISR that is invoked after the completion of I/O
Answer (A)
In both Synchronous and Asynchronous, an interrupt is generated on completion of I/O. In Synchronous, interrupt is generated to wake up the process waiting for I/O. In Asynchronous, interrupt is generated to inform the process that the I/O is complete and it can process the data from the I/O operation. See this for more details.
42) A process executes the following code
for (i = 0; i < n; i++)
fork();
The total number of
child processes created is
(A) n
(B) 2^n - 1
(C) 2^n
(D) 2^(n+1) - 1;
Answer (B)
(A) n
(B) 2^n - 1
(C) 2^n
(D) 2^(n+1) - 1;
Answer (B)
F0 // There will be 1 child process created
by first fork
/ \
F1 F1
// There will be 2 child processes created by second fork
/ \
/ \
F2 F2
F2 F2 // There will be 4 child processes created by
third fork
/ \ / \ / \ / \
............... // and so on
If we sum all levels of above tree
for i = 0 to n-1, we get 2^n - 1. So there will be 2^n – 1 child processes.
Also see this post for more details.
43) Which of the following is NOT true of deadlock prevention and deadlock avoidance schemes?
(A) In deadlock prevention, the request for resources is always granted if the resulting state is safe
(B) In deadlock avoidance, the request for resources is always granted if the result state is safe
(C) Deadlock avoidance is less restrictive than deadlock prevention
(D) Deadlock avoidance requires knowledge of resource requirements a priori
Answer (A)
Deadlock prevention scheme handles deadlock by making sure that one of the four necessary conditions don't occur. In deadlock prevention, the request for a resource may not be granted even if the resulting state is safe. (See the Galvin book slides for more details)
44) A processor uses 36 bit physical addresses and 32 bit virtual addresses, with a page frame size of 4 Kbytes. Each page table entry is of size 4 bytes. A three level page table is used for virtual to physical address translation, where the virtual address is used as follows
• Bits 30-31 are used to index into the first level page table
• Bits 21-29 are used to index into the second level page table
• Bits 12-20 are used to index into the third level page table, and
• Bits 0-11 are used as offset within the page
The number of bits required for addressing the next level page table (or page frame) in the page table entry of the first, second and third level page tables are respectively
(A) 20, 20 and 20
(B) 24, 24 and 24
(C) 24, 24 and 20
(D) 25, 25 and 24
Answer (D)
Virtual address size = 32 bits
Physical address size = 36 bits
Physical memory size = 2^36 bytes
Page frame size = 4K bytes = 2^12 bytes
No. of bits required to access physical memory frame = 36 - 12 = 24
So in third level of page table, 24 bits are required to access an entry.
9 bits of virtual address are used to access second level page table entry and size of pages in second level is 4 bytes. So size of second level page table is (2^9)*4 = 2^11 bytes. It means there are (2^36)/(2^11) possible locations to store this page table. Therefore the second page table requires 25 bits to address it. Similarly, the third page table needs 25 bits to address it.
45) Consider a disk pack with 16 surfaces, 128 tracks per surface and 256 sectors per track. 512 bytes of data are stored in a bit serial manner in a sector. The capacity of the disk pack and the number of bits required to specify a particular sector in the disk are respectively:
(A) 256 Mbyte, 19 bits
(B) 256 Mbyte, 28 bits
(C) 512 Mbyte, 20 bits
(D) 64 Gbyte, 28 bits
Answer (A)
Capacity of the disk = 16 surfaces X 128 tracks X 256 sectors X 512 bytes = 256 Mbytes.
To calculate number of bits required to access a sector, we need to know total number of sectors. Total number of sectors = 16 surfaces X 128 tracks X 256 sectors = 2^19
So the number of bits required to access a sector is 19.
46) Group 1 contains some CPU scheduling algorithms and Group 2 contains some applications. Match entries in Group 1 to entries in Group 2.
43) Which of the following is NOT true of deadlock prevention and deadlock avoidance schemes?
(A) In deadlock prevention, the request for resources is always granted if the resulting state is safe
(B) In deadlock avoidance, the request for resources is always granted if the result state is safe
(C) Deadlock avoidance is less restrictive than deadlock prevention
(D) Deadlock avoidance requires knowledge of resource requirements a priori
Answer (A)
Deadlock prevention scheme handles deadlock by making sure that one of the four necessary conditions don't occur. In deadlock prevention, the request for a resource may not be granted even if the resulting state is safe. (See the Galvin book slides for more details)
44) A processor uses 36 bit physical addresses and 32 bit virtual addresses, with a page frame size of 4 Kbytes. Each page table entry is of size 4 bytes. A three level page table is used for virtual to physical address translation, where the virtual address is used as follows
• Bits 30-31 are used to index into the first level page table
• Bits 21-29 are used to index into the second level page table
• Bits 12-20 are used to index into the third level page table, and
• Bits 0-11 are used as offset within the page
The number of bits required for addressing the next level page table (or page frame) in the page table entry of the first, second and third level page tables are respectively
(A) 20, 20 and 20
(B) 24, 24 and 24
(C) 24, 24 and 20
(D) 25, 25 and 24
Answer (D)
Virtual address size = 32 bits
Physical address size = 36 bits
Physical memory size = 2^36 bytes
Page frame size = 4K bytes = 2^12 bytes
No. of bits required to access physical memory frame = 36 - 12 = 24
So in third level of page table, 24 bits are required to access an entry.
9 bits of virtual address are used to access second level page table entry and size of pages in second level is 4 bytes. So size of second level page table is (2^9)*4 = 2^11 bytes. It means there are (2^36)/(2^11) possible locations to store this page table. Therefore the second page table requires 25 bits to address it. Similarly, the third page table needs 25 bits to address it.
45) Consider a disk pack with 16 surfaces, 128 tracks per surface and 256 sectors per track. 512 bytes of data are stored in a bit serial manner in a sector. The capacity of the disk pack and the number of bits required to specify a particular sector in the disk are respectively:
(A) 256 Mbyte, 19 bits
(B) 256 Mbyte, 28 bits
(C) 512 Mbyte, 20 bits
(D) 64 Gbyte, 28 bits
Answer (A)
Capacity of the disk = 16 surfaces X 128 tracks X 256 sectors X 512 bytes = 256 Mbytes.
To calculate number of bits required to access a sector, we need to know total number of sectors. Total number of sectors = 16 surfaces X 128 tracks X 256 sectors = 2^19
So the number of bits required to access a sector is 19.
46) Group 1 contains some CPU scheduling algorithms and Group 2 contains some applications. Match entries in Group 1 to entries in Group 2.
Group I Group II
(P) Gang Scheduling
(1) Guaranteed Scheduling
(Q) Rate Monotonic Scheduling
(2) Real-time Scheduling
(R) Fair Share Scheduling
(3) Thread Scheduling
(A) P – 3 Q – 2 R – 1
(B) P – 1 Q – 2 R – 3
(C) P – 2 Q – 3 R – 1
(D) P – 1 Q – 3 R – 2
Answer (A)
Gang scheduling for parallel systems that schedules related threads or processes to run simultaneously on different processors.
Rate monotonic scheduling is used in real-time operating systems with a static-priority scheduling class. The static priorities are assigned on the basis of the cycle duration of the job: the shorter the cycle duration is, the higher is the job’s priority.
Fair Share Scheduling is a scheduling strategy in which the CPU usage is equally distributed among system users or groups, as opposed to equal distribution among processes. It is also known as Guaranteed scheduling.
47) An operating system uses Shortest Remaining Time first (SRT) process scheduling algorithm. Consider the arrival times and execution times for the following processes:
(B) P – 1 Q – 2 R – 3
(C) P – 2 Q – 3 R – 1
(D) P – 1 Q – 3 R – 2
Answer (A)
Gang scheduling for parallel systems that schedules related threads or processes to run simultaneously on different processors.
Rate monotonic scheduling is used in real-time operating systems with a static-priority scheduling class. The static priorities are assigned on the basis of the cycle duration of the job: the shorter the cycle duration is, the higher is the job’s priority.
Fair Share Scheduling is a scheduling strategy in which the CPU usage is equally distributed among system users or groups, as opposed to equal distribution among processes. It is also known as Guaranteed scheduling.
47) An operating system uses Shortest Remaining Time first (SRT) process scheduling algorithm. Consider the arrival times and execution times for the following processes:
Process Execution time Arrival time
P1 20 0
P2 25 15
P3 10 30
P4 15 45
What is the total
waiting time for process P2?
(A) 5
(B) 15
(C) 40
(D) 55
Answer (B)
At time 0, P1 is the only process, P1 runs for 15 time units.
At time 15, P2 arrives, but P1 has the shortest remaining time. So P1 continues for 5 more time units.
At time 20, P2 is the only process. So it runs for 10 time units
At time 30, P3 is the shortest remaining time process. So it runs for 10 time units
At time 40, P2 runs as it is the only process. P2 runs for 5 time units.
At time 45, P3 arrives, but P2 has the shortest remaining time. So P2 continues for 10 more time units.
P2 completes its ececution at time 55
(A) 5
(B) 15
(C) 40
(D) 55
Answer (B)
At time 0, P1 is the only process, P1 runs for 15 time units.
At time 15, P2 arrives, but P1 has the shortest remaining time. So P1 continues for 5 more time units.
At time 20, P2 is the only process. So it runs for 10 time units
At time 30, P3 is the shortest remaining time process. So it runs for 10 time units
At time 40, P2 runs as it is the only process. P2 runs for 5 time units.
At time 45, P3 arrives, but P2 has the shortest remaining time. So P2 continues for 10 more time units.
P2 completes its ececution at time 55
Total waiting time for P2 = Complition time - (Arrival time + Execution
time)
= 55 -
(15 + 25)
=
15
48) A virtual memory
system uses First In First Out (FIFO) page replacement policy and allocates a
fixed number of frames to a process. Consider the following statements:
P: Increasing the number of page frames allocated to a process sometimes increases the page fault rate.
Q: Some programs do not exhibit locality of reference. Which one of the following is TRUE?
(A) Both P and Q are true, and Q is the reason for P
(B) Both P and Q are true, but Q is not the reason for P.
(C) P is false, but Q is true
(D) Both P and Q are false.
Answer (B)
P is true. Increasing the number of page frames allocated to process may increases the no. of page faults (See Belady’s Anomaly).
Q is also true, but Q is not the reason for-P as Belady’s Anomaly occurs for some specific patterns of page references.
49) A single processor system has three resource types X, Y and Z, which are shared by three processes. There are 5 units of each resource type. Consider the following scenario, where the column alloc denotes the number of units of each resource type allocated to each process, and the column request denotes the number of units of each resource type requested by a process in order to complete execution. Which of these processes will finish LAST?
alloc request X Y Z X Y Z P0 1 2 1 1 0 3 P1 2 0 1 0 1 2 P2 2 2 1 1 2 0 (A) P0
(B) P1
(C) P2
(D) None of the above, since the system is in a deadlock
Answer (C)
Once all resources (5, 4 and 3 instances of X, Y and Z respectively) are allocated, 0, 1 and 2 instances of X, Y and Z are left. Only needs of P1 can be satisfied. So P1 can finish its execution first. Once P1 is done, it releases 2, 1 and 3 units of X, Y and Z respectively. Among P0 and P2, needs of P0 can only be satisfied. So P0 finishes its execution. Finally, P2 finishes its execution.
50) Two processes, P1 and P2, need to access a critical section of code. Consider the following synchronization construct used by the processes:Here, wants1 and wants2 are shared variables, which are initialized to false. Which one of the following statements is TRUE about the above construct?
/* P1 */ while (true) { wants1 = true; while (wants2 == true); /* Critical Section */ wants1=false; } /* Remainder section */ /* P2 */ while (true) { wants2 = true; while (wants1==true); /* Critical Section */ wants2 = false; } /* Remainder section */ (A) It does not ensure mutual exclusion.
(B) It does not ensure bounded waiting.
(C) It requires that processes enter the critical section in strict alternation.
(D) It does not prevent deadlocks, but ensures mutual exclusion.
Answer (D)
The above synchronization constructs don’t prevent deadlock. When both wants1 and wants2 become true, both P1 and P2 stuck forever in their while loops waiting for each other to finish.
51) Consider the following statements about user level threads and kernel level threads. Which one of the following statement is FALSE?
(A) Context switch time is longer for kernel level threads than for user level threads.
(B) User level threads do not need any hardware support.
(C) Related kernel level threads can be scheduled on different processors in a multi-processor system.
(D) Blocking one kernel level thread blocks all related threads.
Answer (D)
Since kernel level threads are managed by kernel, blocking one thread doesn’t cause all related threads to block. It’s a problem with user level threads. See this for more details.
52) Consider three CPU-intensive processes, which require 10, 20 and 30 time units and arrive at times 0, 2 and 6, respectively. How many context switches are needed if the operating system implements a shortest remaining time first scheduling algorithm? Do not count the context switches at time zero and at the end.
(A) 1
(B) 2
(C) 3
(D) 4
Answer (B)
Let three process be P0, P1 and P2 with arrival times 0, 2 and 6 respectively and CPU burst times 10, 20 and 30 respectively. At time 0, P0 is the only available process so it runs. At time 2, P1 arrives, but P0 has the shortest remaining time, so it continues. At time 6, P2 arrives, but P0 has the shortest remaining time, so it continues. At time 10, P1 is scheduled as it is the shortest remaining time process. At time 30, P2 is scheduled. Only two context switches are needed. P0 to P1 and P1 to P2.
53) A computer system supports 32-bit virtual addresses as well as 32-bit physical addresses. Since the virtual address space is of the same size as the physical address space, the operating system designers decide to get rid of the virtual memory entirely. Which one of the following is true?
(A) Efficient implementation of multi-user support is no longer possible
(B) The processor cache organization can be made more efficient now
(C) Hardware support for memory management is no longer needed
(D) CPU scheduling can be made more efficient now
Answer (C)
For supporting virtual memory, special hardware support is needed from Memory Management Unit. Since operating system designers decide to get rid of the virtual memory entirely, hardware support for memory management is no longer needed
54) A CPU generates 32-bit virtual addresses. The page size is 4 KB. The processor has a translation look-aside buffer (TLB) which can hold a total of 128 page table entries and is 4-way set associative. The minimum size of the TLB tag is:
(A) 11 bits
(B) 13 bits
(C) 15 bits
(D) 20 bits
Answer (C)
Size of a page = 4KB = 2^12
Total number of bits needed to address a page frame = 32 – 12 = 20
If there are ‘n’ cache lines in a set, the cache placement is called n-way set associative. Since TLB is 4 way set associative and can hold total 128 (2^7) page table entries, number of sets in cache = 2^7/4 = 2^5. So 5 bits are needed to address a set, and 15 (20 – 5) bits are needed for tag.
55) Consider three processes (process id 0, 1, 2 respectively) with compute time bursts 2, 4 and 8 time units. All processes arrive at time zero. Consider the longest remaining time first (LRTF) scheduling algorithm. In LRTF ties are broken by giving priority to the process with the lowest process id. The average turn around time is:
(A) 13 units
(B) 14 units
(C) 15 units
(D) 16 units
Answer (A)
Let the processes be p0, p1 and p2. These processes will be executed in following order.
P: Increasing the number of page frames allocated to a process sometimes increases the page fault rate.
Q: Some programs do not exhibit locality of reference. Which one of the following is TRUE?
(A) Both P and Q are true, and Q is the reason for P
(B) Both P and Q are true, but Q is not the reason for P.
(C) P is false, but Q is true
(D) Both P and Q are false.
Answer (B)
P is true. Increasing the number of page frames allocated to process may increases the no. of page faults (See Belady’s Anomaly).
Q is also true, but Q is not the reason for-P as Belady’s Anomaly occurs for some specific patterns of page references.
49) A single processor system has three resource types X, Y and Z, which are shared by three processes. There are 5 units of each resource type. Consider the following scenario, where the column alloc denotes the number of units of each resource type allocated to each process, and the column request denotes the number of units of each resource type requested by a process in order to complete execution. Which of these processes will finish LAST?
alloc request X Y Z X Y Z P0 1 2 1 1 0 3 P1 2 0 1 0 1 2 P2 2 2 1 1 2 0 (A) P0
(B) P1
(C) P2
(D) None of the above, since the system is in a deadlock
Answer (C)
Once all resources (5, 4 and 3 instances of X, Y and Z respectively) are allocated, 0, 1 and 2 instances of X, Y and Z are left. Only needs of P1 can be satisfied. So P1 can finish its execution first. Once P1 is done, it releases 2, 1 and 3 units of X, Y and Z respectively. Among P0 and P2, needs of P0 can only be satisfied. So P0 finishes its execution. Finally, P2 finishes its execution.
50) Two processes, P1 and P2, need to access a critical section of code. Consider the following synchronization construct used by the processes:Here, wants1 and wants2 are shared variables, which are initialized to false. Which one of the following statements is TRUE about the above construct?
/* P1 */ while (true) { wants1 = true; while (wants2 == true); /* Critical Section */ wants1=false; } /* Remainder section */ /* P2 */ while (true) { wants2 = true; while (wants1==true); /* Critical Section */ wants2 = false; } /* Remainder section */ (A) It does not ensure mutual exclusion.
(B) It does not ensure bounded waiting.
(C) It requires that processes enter the critical section in strict alternation.
(D) It does not prevent deadlocks, but ensures mutual exclusion.
Answer (D)
The above synchronization constructs don’t prevent deadlock. When both wants1 and wants2 become true, both P1 and P2 stuck forever in their while loops waiting for each other to finish.
51) Consider the following statements about user level threads and kernel level threads. Which one of the following statement is FALSE?
(A) Context switch time is longer for kernel level threads than for user level threads.
(B) User level threads do not need any hardware support.
(C) Related kernel level threads can be scheduled on different processors in a multi-processor system.
(D) Blocking one kernel level thread blocks all related threads.
Answer (D)
Since kernel level threads are managed by kernel, blocking one thread doesn’t cause all related threads to block. It’s a problem with user level threads. See this for more details.
52) Consider three CPU-intensive processes, which require 10, 20 and 30 time units and arrive at times 0, 2 and 6, respectively. How many context switches are needed if the operating system implements a shortest remaining time first scheduling algorithm? Do not count the context switches at time zero and at the end.
(A) 1
(B) 2
(C) 3
(D) 4
Answer (B)
Let three process be P0, P1 and P2 with arrival times 0, 2 and 6 respectively and CPU burst times 10, 20 and 30 respectively. At time 0, P0 is the only available process so it runs. At time 2, P1 arrives, but P0 has the shortest remaining time, so it continues. At time 6, P2 arrives, but P0 has the shortest remaining time, so it continues. At time 10, P1 is scheduled as it is the shortest remaining time process. At time 30, P2 is scheduled. Only two context switches are needed. P0 to P1 and P1 to P2.
53) A computer system supports 32-bit virtual addresses as well as 32-bit physical addresses. Since the virtual address space is of the same size as the physical address space, the operating system designers decide to get rid of the virtual memory entirely. Which one of the following is true?
(A) Efficient implementation of multi-user support is no longer possible
(B) The processor cache organization can be made more efficient now
(C) Hardware support for memory management is no longer needed
(D) CPU scheduling can be made more efficient now
Answer (C)
For supporting virtual memory, special hardware support is needed from Memory Management Unit. Since operating system designers decide to get rid of the virtual memory entirely, hardware support for memory management is no longer needed
54) A CPU generates 32-bit virtual addresses. The page size is 4 KB. The processor has a translation look-aside buffer (TLB) which can hold a total of 128 page table entries and is 4-way set associative. The minimum size of the TLB tag is:
(A) 11 bits
(B) 13 bits
(C) 15 bits
(D) 20 bits
Answer (C)
Size of a page = 4KB = 2^12
Total number of bits needed to address a page frame = 32 – 12 = 20
If there are ‘n’ cache lines in a set, the cache placement is called n-way set associative. Since TLB is 4 way set associative and can hold total 128 (2^7) page table entries, number of sets in cache = 2^7/4 = 2^5. So 5 bits are needed to address a set, and 15 (20 – 5) bits are needed for tag.
55) Consider three processes (process id 0, 1, 2 respectively) with compute time bursts 2, 4 and 8 time units. All processes arrive at time zero. Consider the longest remaining time first (LRTF) scheduling algorithm. In LRTF ties are broken by giving priority to the process with the lowest process id. The average turn around time is:
(A) 13 units
(B) 14 units
(C) 15 units
(D) 16 units
Answer (A)
Let the processes be p0, p1 and p2. These processes will be executed in following order.
p2 p1
p2 p1 p2 p0 p1
p2 p0 p1
p2
0 4 5
6 7 8 9 10
11 12 13
14
Turn around time of a process is
total time between submission of the process and its completion.
Turn around time of p0 = 12 (12-0)
Turn around time of p1 = 13 (13-0)
Turn around time of p2 = 14 (14-0)
Average turn around time is (12+13+14)/3 = 13.
56) Consider three processes, all arriving at time zero, with total execution time of 10, 20 and 30 units, respectively. Each process spends the first 20% of execution time doing I/O, the next 70% of time doing computation, and the last 10% of time doing I/O again. The operating system uses a shortest remaining compute time first scheduling algorithm and schedules a new process either when the running process gets blocked on I/O or when the running process finishes its compute burst. Assume that all I/O operations can be overlapped as much as possible. For what percentage of time does the CPU remain idle?(A) 0%
(B) 10.6%
(C) 30.0%
(D) 89.4%
Answer (B)
Let three processes be p0, p1 and p2. Their execution time is 10, 20 and 30 respectively. p0 spends first 2 time units in I/O, 7 units of CPU time and finally 1 unit in I/O. p1 spends first 4 units in I/O, 14 units of CPU time and finally 2 units in I/O. p2 spends first 6 units in I/O, 21 units of CPU time and finally 3 units in I/O.
Turn around time of p0 = 12 (12-0)
Turn around time of p1 = 13 (13-0)
Turn around time of p2 = 14 (14-0)
Average turn around time is (12+13+14)/3 = 13.
56) Consider three processes, all arriving at time zero, with total execution time of 10, 20 and 30 units, respectively. Each process spends the first 20% of execution time doing I/O, the next 70% of time doing computation, and the last 10% of time doing I/O again. The operating system uses a shortest remaining compute time first scheduling algorithm and schedules a new process either when the running process gets blocked on I/O or when the running process finishes its compute burst. Assume that all I/O operations can be overlapped as much as possible. For what percentage of time does the CPU remain idle?(A) 0%
(B) 10.6%
(C) 30.0%
(D) 89.4%
Answer (B)
Let three processes be p0, p1 and p2. Their execution time is 10, 20 and 30 respectively. p0 spends first 2 time units in I/O, 7 units of CPU time and finally 1 unit in I/O. p1 spends first 4 units in I/O, 14 units of CPU time and finally 2 units in I/O. p2 spends first 6 units in I/O, 21 units of CPU time and finally 3 units in I/O.
idle p0
p1 p2 idle
0 2 9
23 44 47
Total time spent = 47
Idle time = 2 + 3 = 5
Percentage of idle time = (5/47)*100 = 10.6 %
57) The atomic fetch-and-set x, y instruction unconditionally sets the memory location x to 1 and fetches the old value of x in y without allowing any intervening access to the memory location x. consider the following implementation of P and V functions on a binary semaphore .
void P (binary_semaphore *s) {
unsigned y;
unsigned *x =
&(s->value);
do {
fetch-and-set x, y;
} while (y);
}
void V (binary_semaphore *s) {
S->value = 0;
}
Which one of the
following is true?
(A) The implementation may not work if context switching is disabled in P.
(B) Instead of using fetch-and-set, a pair of normal load/store can be used
(C) The implementation of V is wrong
(D) The code does not implement a binary semaphore
Answer (A)
Let us talk about the operation P(). It stores the value of s in x, then it fetches the old value of x, stores it in y and sets x as 1. The while loop of a process will continue forever if some other process doesn’t execute V() and sets the value of s as 0. If context switching is disabled in P, the while loop will run forever as no other process will be able to execute V().
58) Consider the following snapshot of a system running n processes. Process i is holding Xi instances of a resource R, 1 <= i <= n. currently, all instances of R are occupied. Further, for all i, process i has placed a request for an additional Yi instances while holding the Xi instances it already has. There are exactly two processes p and q such that Yp = Yq = 0. Which one of the following can serve as a necessary condition to guarantee that the system is not approaching a deadlock?
(A) min (Xp, Xq) < max (Yk) where k != p and k != q
(B) Xp + Xq >= min (Yk) where k != p and k != q
(C) max (Xp, Xq) > 1
(D) min (Xp, Xq) > 1
Answer (B)
Since both p and q don’t need additional resources, they both can finish and release Xp + Xq resources without asking for any additional resource. If the resources released by p and q are sufficient for another process waiting for Yk resources, then system is not approaching deadlock.
59) Normally user programs are prevented from handling I/O directly by I/O instructions in them. For CPUs having explicit I/O instructions, such I/O protection is ensured by having the I/O instructions privileged. In a CPU with memory mapped I/O, there is no explicit I/O instruction. Which one of the following is true for a CPU with memory mapped I/O?
(a) I/O protection is ensured by operating system routine(s)
(b) I/O protection is ensured by a hardware trap
(c) I/O protection is ensured during system configuration
(d) I/O protection is not possible
Answwer (a)
Memory mapped I/O means, accessing I/O via general memory access as opposed to specialized IO instructions. An example,
(A) The implementation may not work if context switching is disabled in P.
(B) Instead of using fetch-and-set, a pair of normal load/store can be used
(C) The implementation of V is wrong
(D) The code does not implement a binary semaphore
Answer (A)
Let us talk about the operation P(). It stores the value of s in x, then it fetches the old value of x, stores it in y and sets x as 1. The while loop of a process will continue forever if some other process doesn’t execute V() and sets the value of s as 0. If context switching is disabled in P, the while loop will run forever as no other process will be able to execute V().
58) Consider the following snapshot of a system running n processes. Process i is holding Xi instances of a resource R, 1 <= i <= n. currently, all instances of R are occupied. Further, for all i, process i has placed a request for an additional Yi instances while holding the Xi instances it already has. There are exactly two processes p and q such that Yp = Yq = 0. Which one of the following can serve as a necessary condition to guarantee that the system is not approaching a deadlock?
(A) min (Xp, Xq) < max (Yk) where k != p and k != q
(B) Xp + Xq >= min (Yk) where k != p and k != q
(C) max (Xp, Xq) > 1
(D) min (Xp, Xq) > 1
Answer (B)
Since both p and q don’t need additional resources, they both can finish and release Xp + Xq resources without asking for any additional resource. If the resources released by p and q are sufficient for another process waiting for Yk resources, then system is not approaching deadlock.
59) Normally user programs are prevented from handling I/O directly by I/O instructions in them. For CPUs having explicit I/O instructions, such I/O protection is ensured by having the I/O instructions privileged. In a CPU with memory mapped I/O, there is no explicit I/O instruction. Which one of the following is true for a CPU with memory mapped I/O?
(a) I/O protection is ensured by operating system routine(s)
(b) I/O protection is ensured by a hardware trap
(c) I/O protection is ensured during system configuration
(d) I/O protection is not possible
Answwer (a)
Memory mapped I/O means, accessing I/O via general memory access as opposed to specialized IO instructions. An example,
unsigned int volatile const
*pMappedAddress const = (unsigned int *)0x100;
So, the programmer can directly
access any memory location directly. To prevent such an access, the OS (kernel)
will divide the address space into kernel space and user space. An user
application can easily access user application. To access kernel space, we need
system calls (traps).
60) What is the swap space in the disk used for?
(a) Saving temporary html pages
(b) Saving process data
(c) Storing the super-block
(d) Storing device drivers
Answer (b)
Swap space is typically used to store process data. See this for more details.
61) Increasing the RAM of a computer typically improves performance because:
(a) Virtual memory increases
(b) Larger RAMs are faster
(c) Fewer page faults occur
(d) Fewer segmentation faults occur
Answer (c)
62) Suppose n processes, P1, …. Pn share m identical resource units, which can be reserved and released one at a time. The maximum resource requirement of process Pi is Si, where Si > 0. Which one of the following is a sufficient condition for ensuring that deadlock does not occur?

Answer (c)
In the extreme condition, all processes acquire Si-1 resources and need 1 more resource. So following condition must be true to make sure that deadlock never occurs.
 < m
< m
The above expression can be written as following.
 < (m + n)
< (m + n)
See this forum thread for an example.
63) Consider the following code fragment:
60) What is the swap space in the disk used for?
(a) Saving temporary html pages
(b) Saving process data
(c) Storing the super-block
(d) Storing device drivers
Answer (b)
Swap space is typically used to store process data. See this for more details.
61) Increasing the RAM of a computer typically improves performance because:
(a) Virtual memory increases
(b) Larger RAMs are faster
(c) Fewer page faults occur
(d) Fewer segmentation faults occur
Answer (c)
62) Suppose n processes, P1, …. Pn share m identical resource units, which can be reserved and released one at a time. The maximum resource requirement of process Pi is Si, where Si > 0. Which one of the following is a sufficient condition for ensuring that deadlock does not occur?

Answer (c)
In the extreme condition, all processes acquire Si-1 resources and need 1 more resource. So following condition must be true to make sure that deadlock never occurs.
< mThe above expression can be written as following.
< (m + n)See this forum thread for an example.
63) Consider the following code fragment:
if (fork() == 0)
{ a = a + 5; printf(“%d,%d\n”,
a, &a); }
else { a = a –5; printf(“%d,
%d\n”, a, &a); }
Let u, v be the values
printed by the parent process, and x, y be the values printed by the child
process. Which one of the following is TRUE?
(a) u = x + 10 and v = y
(b) u = x + 10 and v != y
(c) u + 10 = x and v = y
(d) u + 10 = x and v != y
Answer (c)
fork() returns 0 in child process and process ID of child process in parent process.
In Child (x), a = a + 5
In Parent (u), a = a – 5;
Therefore x = u + 10.
The physical addresses of ‘a’ in parent and child must be different. But our program accesses virtual addresses (assuming we are running on an OS that uses virtual memory). The child process gets an exact copy of parent process and virtual address of ‘a’ doesn’t change in child process. Therefore, we get same addresses in both parent and child. See this run for example.
64. Fetch_And_Add(X,i) is an atomic Read-Modify-Write instruction that reads the value of memory location X, increments it by the value i, and returns the old value of X. It is used in the pseudocode shown below to implement a busy-wait lock. L is an unsigned integer shared variable initialized to 0. The value of 0 corresponds to lock being available, while any non-zero value corresponds to the lock being not available.
(a) u = x + 10 and v = y
(b) u = x + 10 and v != y
(c) u + 10 = x and v = y
(d) u + 10 = x and v != y
Answer (c)
fork() returns 0 in child process and process ID of child process in parent process.
In Child (x), a = a + 5
In Parent (u), a = a – 5;
Therefore x = u + 10.
The physical addresses of ‘a’ in parent and child must be different. But our program accesses virtual addresses (assuming we are running on an OS that uses virtual memory). The child process gets an exact copy of parent process and virtual address of ‘a’ doesn’t change in child process. Therefore, we get same addresses in both parent and child. See this run for example.
64. Fetch_And_Add(X,i) is an atomic Read-Modify-Write instruction that reads the value of memory location X, increments it by the value i, and returns the old value of X. It is used in the pseudocode shown below to implement a busy-wait lock. L is an unsigned integer shared variable initialized to 0. The value of 0 corresponds to lock being available, while any non-zero value corresponds to the lock being not available.
AcquireLock(L){
while
(Fetch_And_Add(L,1))
L = 1;
}
ReleaseLock(L){
L = 0;
}
This implementation
(A) fails as L can overflow
(B) fails as L can take on a non-zero value when the lock is actually available
(C) works correctly but may starve some processes
(D) works correctly without starvation
Answer (B)
Take closer look the below while loop.
(A) fails as L can overflow
(B) fails as L can take on a non-zero value when the lock is actually available
(C) works correctly but may starve some processes
(D) works correctly without starvation
Answer (B)
Take closer look the below while loop.
while (Fetch_And_Add(L,1))
L = 1; // A waiting process can be here just after
// the lock
is released, and can make L = 1.
Consider a situation where a
process has just released the lock and made L = 0. Let there be one more
process waiting for the lock, means executing the AcquireLock() function. Just
after the L was made 0, let the waiting processes executed the line L = 1. Now,
the lock is available and L = 1. Since L is 1, the waiting process (and any
other future coming processes) can not come out of the while loop.
The above problem can be resolved by changing the AcuireLock() to following.
The above problem can be resolved by changing the AcuireLock() to following.
AcquireLock(L){
while
(Fetch_And_Add(L,1))
{ // Do Nothing }
}
No comments:
Post a Comment